Hacksgiving 2024
Team Members - Alhagie Boye, Caleb Gray, Sonia Grade, Autumn Mizer, Alex Neher, Olek Drobek, Bart Gebka
Building “Discovery Mate”
Our Winning
AI-Powered Museum Assistant
At Hacksgiving 2024, hosted by Discovery World and Milwaukee School of Engineering (MSOE), our team clinched first place with Discovery Mate — an AI-driven platform designed to expand access to museum exhibits through voice, adaptive content, and hyper-personalization. Competing against 10+ teams, we stood out by merging cutting-edge AI with practical accessibility.

Alhagie Boye, (third from the left) poses with fellow Discovery Mate Team members at the 2024 MSOE Hacksgiving. From left to right: Olek Drobek, Caleb Gray, Alhagie Boye, Alex Neher, Autumn Mizer, Ben Paulson, Evan Jackson '23, D.R Jeremy Kedziora and D.R Bardunias.
HacksGiving Problem Statement
Discovery World, Milwaukee’s premier non-profit science and technology center, aims to create more immersive and
accessible experiences for its diverse visitors. Consequently, the challenge for Hacksgiving 2024 was to design an
AI-driven solution that enhances visitor interactions with exhibits.
Imagine engaging both a curious five-year-old and a seasoned expert, breaking down language barriers, or even
connecting related exhibits across the museum for a richer learning experience!
Our task was to create an AI solution that effectively addressed this theme while ensuring it remained intuitive,
accessible, and scalable for all visitors.
Discovery Mate
Discovery Mate is an inclusive, multilingual AI platform designed to enhance museum experiences through real-time
voice interaction, personalized exhibit recommendations, and adaptive content delivery. Key features include:
- • Exhibit Recommendation Engine (XRE): Uses user preferences, visit history, and exhibit popularity to suggest the most relevant exhibits.
- • AI-Generated Exhibit Texts: Employs a custom Retrieval-Augmented Generation (RAG) pipeline to generate personalized exhibit descriptions.
- • Voice Assitant: It utilizes LiveKit for real-time voice communication, ensuring fluid interactions. Voice Assistant is interruptible with real-time language switching.
- • Multilingual Chat-Bot: A text-based chat-bot that supports over 100 languages and uses a custom Retrieval-Augmented Generation (RAG) pipeline for real-time responses.
- • Education Levels: Simplifies explanations for elementary students or adds depth for college visitors to make the exhibits accessible to a wide range of visitors.
- • Multilingual Page Translation: Utilizes Microsoft Translator to translate exhibit content and museum pages in over 100 languages.
- • Text-to-Speech: Converts exhibit descriptions and chatbot responses into speech, enhancing accessibility and engagement for visitors.
- • Custom AI Framework: Developed to minimize hallucinations, ensuring that generated responses are accurate and aligned with the museum's content.
Retrieval Augmented Generation (RAG) Pipeline
With the increased popularity and use of Large Language Models in the past few years, it is increasingly clear
that they are generally unreliable and may hallucinate information. Hallucination refers to when the model
generates information that is false, misleading, or completely fabricated, even though it may appear to be correct
or plausible. Additionally, LLMs have a great amount of content memorized during training, which might differ from
the information we want our model to have access to and use. Retrieval Augmented
Generation is our solution for this, as it uses a custom knowledge base embedded in a
vector database to add relevant, accurate information to
queries to enhance the output of the model. When a user makes a query, the top k context documents from the custom
knowledge base are added to the query for more context. Our custom knowledge base includes extensive information
about each exhibit.
RAG Pipeline
Custom RAG Pipeline to Prevent Hallucination.
The first enhancement we make to the RAG pipeline is with query enhancement, using an LLM to add further context about the current user and exhibit information, before doing document retrieval from the vector database for retrieval augmented generation. After doing this, we use another LLM for smart translation (for translating idioms, analogies, and keeping the content tailored to culture correctly) and tailoring the output to specific age/complexity groups. Current research indicates the translation method we use with Google’s Gemini model outperforms Google Translate functionality. The need for language and age augmentation is determined when the query is called using smart evaluation, meaning that we keep costs low by not doing unnecessary inference of models. The final part of this custom pipeline is LLM as a judge validation to ensure that the output is grounded in relevant information from the custom knowledge base we provide to the model.
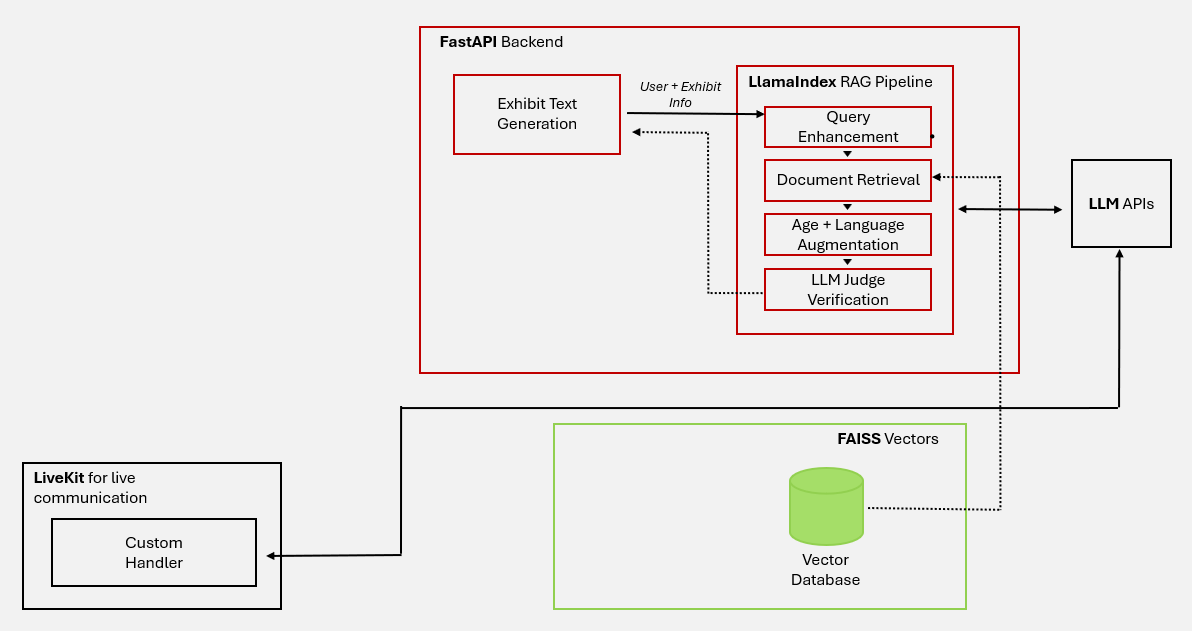
System Diagram

Discovery Mate System Diagram.
The Discovery Mate platform is built on a modular architecture designed to deliver real-time, AI-driven museum experiences. At its core, the system integrates a React-based frontend for user interaction, a FastAPI backend for data orchestration, and a LlamaIndex RAG (Retrieval-Augmented Generation) pipeline for context-aware AI responses. These components work alongside LiveKit for voice communication and multiple databases to store structured and unstructured data, ensuring scalability and accessibility.
Frontend: User and Admin Interfaces
The React frontend serves two primary roles. For visitors, it provides a clean, intuitive interface where users can view exhibit details, receive personalized recommendations, or interact via voice commands. The interface dynamically adjusts content based on language preferences and education levels for example, simplifying explanations for children or adding technical depth for adults. For administrators, a dedicated Admin View allows museum staff to update exhibit metadata, monitor foot traffic analytics, and manage content. Voice interactions are powered by LiveKit, enabling real-time audio streaming and interruptible dialogue, critical for engaging visitors in noisy museum environments.
Backend: Data Orchestration and Logic
The FastAPI backend acts as the system’s brain, coordinating data flow and business logic. It handles Exhibit Text Generation using large language models like GPT-4, producing multilingual descriptions tailored to user demographics. The Exhibit Recommendation Engine (XRE) combines collaborative and content-based filtering to suggest exhibits for instance, guiding a robotics enthusiast to the Control Cabinet after they visit the Dream Machine. A CRUD API manages database operations, storing user profiles, exhibit metadata, and real-time analytics in PostgreSQL. This backend ensures seamless communication between the frontend, AI pipelines, and databases.
RAG Pipeline: Context-Aware Responses
The LlamaIndex RAG pipeline enhances the system’s intelligence. When a user asks a question (e.g., “How does the laser work?”), the pipeline refines the query by expanding keywords (e.g., “laser” → “CO2 laser, engraving”). It retrieves relevant documents from a FAISS vector database, which stores embeddings of exhibit data and museum knowledge bases. Responses are augmented based on the user’s age and language simplifying explanations for children or adding technical jargon for experts. An LLM Judge cross-checks answers against trusted sources to ensure accuracy, enabling dynamic, trustworthy interactions.
Databases: Structured and Vector Storage
The system relies on multiple databases for efficiency. A tabular database (PostgreSQL) stores structured data like user preferences and exhibit schedules. For unstructured data, a FAISS vector database enables rapid similarity searches critical for retrieving exhibit details or clustering topics (e.g., grouping “CO2 lasers” under “Science & Technology”). A separate vector database stores topic embeddings generated during meta-topic clustering, streamlining recommendation logic. Together, these databases ensure quick access to curated and AI-generated content.
Real-Time Communication with LiveKit
LiveKit powers the platform’s voice-first interface. Its custom handler processes audio streams, converting voice commands into text and routing them to the RAG pipeline. The system supports interruptions (e.g., “Wait, explain that again”), mimicking natural conversation. LiveKit’s scalability allows it to manage hundreds of simultaneous users without latency, even during peak hours. This real-time layer is vital for immersive, hands-free experiences, particularly for visually impaired visitors using Bluetooth headsets.
Integration and Scalability
The architecture’s modular design ensures scalability. During high demand, AWS EC2 instances auto-scale to handle traffic spikes, while LiveKit’s SFU optimizes bandwidth for voice streams. The use of OpenAI and Gemini APIs balances cost and performance, with cached responses reducing reliance on expensive LLM calls. By decoupling components (frontend, backend, AI pipelines), the system allows iterative updates such as swapping FAISS for a different vector database or integrating new LLMs without disrupting user workflows.
Exhibit Recommendation Engine (XRE)
The Exhibit Recommendation Engine (XRE) is a system that recommends exhibits to users based on their interestes, exhibit popularity, and their past exhibits.
Preprocessing Exhibits into meta topics
Each exhibit came with a list of topics, however this list was too large to be used directly in the recommendation
engine. To reduce the dimensionality of the topics, we used a pre-trained embedding model to embed the topics and
preset meta topics, which were then used to cluster the topics into meta topics. The meta topics were then used to
represent the exhibits.
The following topics were clustered into the following metatopics:

Exhibit Embeddings
Using the meta topics, we create a nine dimensional vector for each exhibit (where each dimension corresponds to a
meta topic). This vector is used to represent the exhibit in the recommendation engine. The embeddings are created
by adding 1 to the corresponding dimension for each topic that belongs to the meta topic and finally dividing by
the max value in the vector (not L2 normalization).
Visualization of exhibit embeddings:

User Embeddings
Before the user can receive recommendations, they must first provide their interests. The user selects how
interested they are in each of the meta topics. The user's interests are then used to create a user embedding,
which is a nine dimensional vector where each dimension corresponds to a meta topic.
These embeddings are then used to calculate the similarity between the user and the exhibits.

Combining Recommendation Factors
Each of the three factors (user interests, exhibit popularity, and user history) are combined to create a final score for each exhibit. The final score is used to rank the exhibits and provide the user with a list of recommended exhibits.
Teamwork
The Discovery Mate was designed and developed in a single 3-day Hacksgiving-2024 hackathon with seven members of team (Alhagie Boye, Caleb Gray, Sonia Grade, Autumn Mizer, Alex Neher, Olek Drobek, and Bart Gebka) who pooled our efforts. We broke up into subteams specializing in frontend work, backend integrations, and AI pipeline setup while checking in regularly with each other. The joint programming setup encouraged pair-programming and cross-disciplined solutions to general integration concerns between LiveKit's voice features and our own custom RAG pipeline. Our approach of combining domain knowledge, and building upon each other's ideas, helped us design, implement, and pitch a highly complex system composed of many integrated components in 72 hours, going on to win first place ahead of more than 10 other teams.
Future Work
- • Use location to recommend exhibits that are close to the user
- • Integrating advanced AR features for interactive exhibits
- • Use time of day to recommend exhibits that are open
- • Use an LLM to generate the final recommendations.
Conclusion
At its heart, Discovery Mate isn’t just code and algorithms it’s about making museums come alive for everyone. By
weaving together tools like React, FastAPI, and LiveKit, we’ve created something that feels less like a tech demo
and more like a friendly guide. Imagine a kid lighting up as the voice assistant explains lasers in simple terms,
or a grandparent switching seamlessly to Mandarin to hear about ancient artifacts. That’s the magic here:
technology that adapts to people, not the other way around.
What makes this special? It’s built to grow. Whether it’s handling a school field trip or a packed weekend crowd,
the system scales quietly behind the scenes. And it’s not just smart, it’s thoughtful. The AI doesn’t just spit
out
facts; it learns what you love, whether you’re into robots, Renaissance art, or rainforest ecosystems. Then it
whispers, “Hey, the next exhibit you’ll adore is just around the corner.”
Winning Hacksgiving 2024 wasn’t about complex algorithms, it was about solving real problems. How do you help a
visually impaired visitor navigate independently? How do you turn a confusing museum map into a curated adventure?
This project proved that when tech prioritizes empathy, it doesn’t just win hackathons, it changes how we explore,
learn, and connect. We’re crafting experiences that stick with you long after you’ve
left the museum doors.
Read MSOE's 2024 HacksGiving blog post